
Die Datenvorverarbeitung beim maschinellen Lernen ist ein entscheidender Schritt, der zur Verbesserung der Datenqualität beiträgt, um die Gewinnung aussagekräftiger Erkenntnisse aus den Daten zu fördern.
Die Datenvorverarbeitung im Machine Learning bezieht sich auf die Technik der Vorbereitung (Bereinigung und Organisation) der Rohdaten, um sie für das Erstellen und Trainieren von Machine Learning-Modellen geeignet zu machen. In einfachen Worten ist die Datenvorverarbeitung im Machine Learning eine Data-Mining-Technik, die Rohdaten in ein verständliches und lesbares Format umwandelt.
In dieser ausführlichen Anleitung stelle ich Ihnen die wesentlichen Schritte der Datenvorverarbeitung im Bereich Machine Learning und insbesondere Deep Learning vor.
Darüber hinaus zeige ich Ihnen, wie Sie diese Schritte in Python implementieren können.
Inhaltsübersicht
- Einführung: Warum brauchen wir Data Preprocessing?
- Numerische Daten
- Skalierung von Daten
- Umgang mit fehlenden Werten im Datensatz
- Umgang mit Ausreißern im Datensatz
- Kategoriale Daten und String-Datentypen
- Kodierung der kategorialen Daten
- One-Hot-Encoding
- Aufteilung der Daten in Training-, Test- und Validierungsdaten
1. Einführung: Warum brauchen wir Datenvorverarbeitung überhaupt?
Wenn Sie ein neuronales Netzwerk trainieren, müssen Sie immer berücksichtigen, dass die Qualität der Trainingsdaten die Qualität Ihres neuronalen Netzes bestimmt. Das bedeutet die Genauigkeit der Vorhersagen eines Modells hängt im Wesentlich davon ab, wie gut die Daten sind, an denen das Modell trainiert worden ist. Aber was genau heißt “Gute Daten”?
“Gute Date”, die sich als Trainingsdaten eignen müssen meiner Meinung nach 4 Kriterien erfüllen.
- Die Daten müssen in in die Kategorien Features und Labels unterteilt werden können. Wir haben diese beiden Begriffe und ihre Bedeutung bereits sehr ausführlich im Artikel Auswahl der Trainingsdaten behandelt. An dieser Stelle möchte ich nicht nochmal darauf eingehen. Ich setze mal voraus, dass Sie bereits mit den Begrifflichkeiten vertraut sind. Falls, nicht empfehle ich Ihnen noch mal den verlinkten Artikel anzuschauen.
- Den Features muss eine gewisse Vorhersagekraft auf die Labels nachgesagt werden. In den meisten Fällen ist hier die genau Kenntnis der Problemdomäne und menschliche Intuition gefragt. Wenn unsere Aufgabe beispielsweise darin besteht eine Vorhersage für den zukünftigen Preis einer Immobilie zu berechnen, dann würden die Features (Lage der Immobilie und das Alter) sich definitiv auf den Preis, das Label, auswirken. Damit haben diese Feature eine Vorhersagekraft. Auf der anderen Seite würde der Feature “Anzahl der vorherigen Besitzer” womöglich keine Bedeutung spielen. Damit könnte man die ersteren beiden benutzten um eine Vorhersage für den erwarteten Immobilienpreis zu treffen.
- Die Daten müssen in einem Format vorliegen, der von dem neuronalen Netz gelesen werden kann. Als Format können hier nur numerische Werte in Fragen, also zahlen. Zeichenketten, wie Wörter, Buchstaben oder gar ganze Sätze können dagegen nicht von einem neuronalen Netz gelesen werden. Allerdings, wie wir später sehen werden, können wir auch Zeichenketten in numerische Werte umwandeln, die dann ebenfalls als Trainingsdaten problemlos benutzt werden können.
- Selbst wenn die Daten in dem richtigen Format vorliegen, heißt das noch lange nicht, dass wir mit Ihnen die bestmögliche Genauigkeit eines neuronalen Netzes. Die Daten müssen sauber, einheitlich und gut strukturiert sein. Das bedeutet, dass ein Datensatz keine fehlenden Werte, Anomalien oder Ausreißer aufweisen darf und die vorhandenen Daten müssen alle in einem ähnlichen Wertebereich liegen.
Aus der Erfahrung kann ich sagen, dass die ersten beiden Kategorien noch am einfachsten zu erfüllen sind. Alleine wegen der unglaublichen Masse an strukturierten Daten, die es heutzutage gibt. Doch auch die Daten, die diese Kriterien erfüllen, auf diese Sie in der Praxis stoßen werden, sind in den meisten Fällen vollkommen ungeeignet um damit ein neuronales Netz zu trainieren.
Das liegt daran, dass diese Daten nicht sauber sein werden. Das bedeutet, dass die Daten nicht einheitliche Datenformate, fehlende Werte, Ausreißer und Daten mit sehr unterschiedlichen Wertebereichen enthalten werden. Aus diesem Grund müssen die Daten auf verschiedene Arten vorverarbeitet werden. Erst wenn die Daten diese vier Kriterien erfüllen, können wir diese als Trainingsdaten benutzten und auch erwartet, dass wir die bestmögliche Genauigkeit unseres neuronalen Netzes erzielen können. Und genau darum wird es in diesem Modul gehen.
Ich werden Ihnen Methoden vorstellen und Tools in die Hand geben, mit denen Sie echte Datensätze vorverarbeiten werden bis alle vier Kriterien erfüllt sind und die Datensätze als Trainingsdaten für ein neuronales Netz verwendet werden können.
Alle Vorverarbeitungsschritte werden zunächst in der Theorie besprochen. Nach jedem Abschnitt werde ich diese Theorie in die Praxis umsetzen und Ihnen zeigen, wie Sie Python verwenden können, um diese Vorverarbeitungsschritte durchzuführen.
Willst Du einen Job in Data Science und AI?
Gerade als Quereinsteiger oder kompletter Berufseinsteiger ist es mittlerweile nahezu unmöglich, einen Job im Bereich AI/Data Science zu ergattern.
Mittlerweile gibt es durchschnittlich einhundert Bewerber auf jede Stelle und es kommt mir so vor, als hätte jeder, der sich bewirbt, bereits mehrere Online-Kurse zum Thema Data Science absolviert und ein halbes Dutzend Zertifikate vorzuweisen.
Ohne aus dieser großen Masse an Kandidaten herauszustechen, landet die Bewerbung schnell im virtuellen Mülleimer.
Als Teamleiter im Bereich KI/Data Science habe ich im Laufe der Jahre Bewerbungen von Hunderten von Kandidaten gesehen. Ich weiß, worauf es ankommt.
Ein Quereinsteiger oder Berufseinsteiger ohne nennenswerte Erfahrung hat nur eine Chance, den Job zu bekommen: mit einem umfangreichen Data-Science-Portfolio, das perfekt auf die ausgeschriebene Stelle zugeschnitten ist. Damit überzeugst du die HR und die Entscheidungsträger warum gerade Du der richte Kandidat für die Stelle bist.
Ich unterstütze dich persönlich dabei, ein maßgeschneidertes Data-Science-Projektportfolio zu entwickeln und umzusetzen, das genau auf deine Wunschstelle zugeschnitten ist.
Interesse? Dann, trage unten deinen Namen und Email ein und ich melde mich bei dir mit weiteren Informationen.
2. Numerische Daten
In der ersten Hälfte dieses Artikels stelle ich die häufigsten Vorverarbeitungsschritte für numerische Daten vor. Numerische Daten sind Daten in Form von Skalarwerten. Diese skalaren Werte haben einen kontinuierlichen Wertebereich. Das bedeutet, dass es eine unendliche Anzahl von möglichen Werten gibt.
Strukturierte Daten beziehen sich auf die Art von Daten, die in einer Datenbanktabelle oder einem analysierbaren Format wie einer CSV-Datei (Comma Separated Values) oder Excel Tabelle gefunden werden können. Aus diesem Grund werden diese Daten auch als tabellarische Daten bezeichnen.
Ganzzahlen und Gleitkommazahlen sind die am häufigsten verwendeten numerischen Datentypen. Obwohl numerische Daten direkt in neuronale Netzmodelle eingespeist werden können, kann es sein, dass die Daten einige Vorverarbeitungsschritte erfordern, z. B. wenn der Bereich der Eingangsmerkmale sehr unterschiedlich ist.
3. Skalierung der Features
Es liegt in der Natur der Daten, dass die Wertebereiche in diesen Daten stark variieren. Sie können Features haben, die einen sehr kleinen Wertebereich haben, aber auch Features, die einen großen Wertebereich haben. Stellen Sie sich vor, Ihre Eingabedaten bestehen nur aus zwei Features. Nennen wir diese Features  und
und  . Nehmen wir an, nimmt Werte aus einem kleinen Bereich zwischen 0 und 0,5 an, während die Werte von zwischen 10 und 2500 liegen.
. Nehmen wir an, nimmt Werte aus einem kleinen Bereich zwischen 0 und 0,5 an, während die Werte von zwischen 10 und 2500 liegen.
Können Sie sich vorstellen, warum dies problematisch sein kann, wenn Sie ein neuronales Netz auf diese Daten trainieren?
Um zu erklären, warum dies zu Problemen führen kann, lassen Sie uns ein grafisches Modell verwenden. Das linke Diagramm zeigt den Verlauf einer Verlustfunktion, für die wir die Gewichte suchen, die zu einem globalen Minimum führen. Es fällt auf, dass sehr unterschiedliche Merkmalsbereiche von und diese Verlustfunktion sehr schräg und langwierig machen:
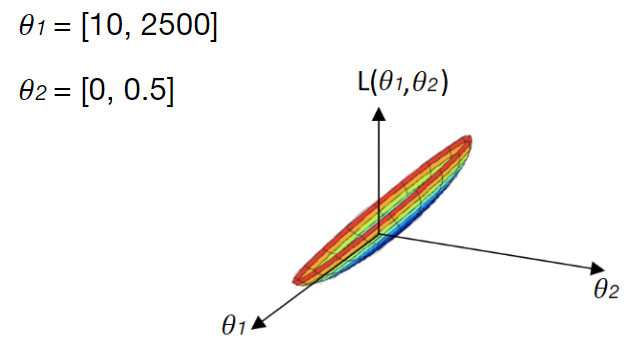
Dies wird noch deutlicher, wenn wir die Konturen der Verlustfunktion unten betrachten:
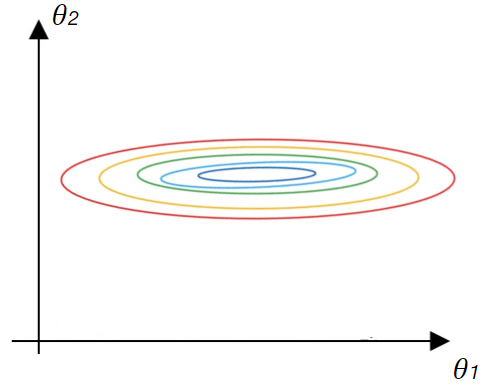
Die roten Bereiche der Konturen zeigen höhere Werte der Verlustfunktion an, während der blaue Bereich die niedrigeren Werte darstellt. Denken Sie daran, dass wir beim Training eines neuronalen Netzes mithilfe des Gradientenabstiegs einen bestimmten Satz von Gewichten finden, der die Verlustfunktion minimiert.
Im Falle einer sehr schiefen Verlustfunktion, wie in diesem Fall, würde der Gradientenabstieg größere Schritte in Richtung der Features mit dem kleineren Wertebereich machen, während er nur kleine Schritte in Richtung der Features mit dem höheren Wertebereich macht.
Der Gradient würde stark oszillieren, was dazu führen würde, dass das Modell längere Zeit bräuchte, um das globale Minimum zu finden:
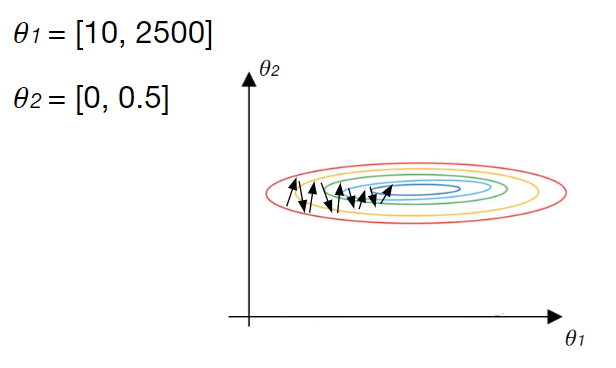
Im schlimmsten Fall könnte das Minimum gar nicht gefunden werden. In der Praxis lässt sich dieses Problem durch die so genannte Merkmalsskalierung vermeiden.
Die Merkmalsskalierung ist eine Methode in der Datenwissenschaft, die dazu dient, den Bereich der unabhängigen Features in einem Datensatz zu standardisieren. Die Merkmalsskalierung würde das genannte Problem verhindern und die Gesamtleistung des Modells verbessern. Schauen wir uns an, wie dies in einem grafischen Modell aussehen würde:
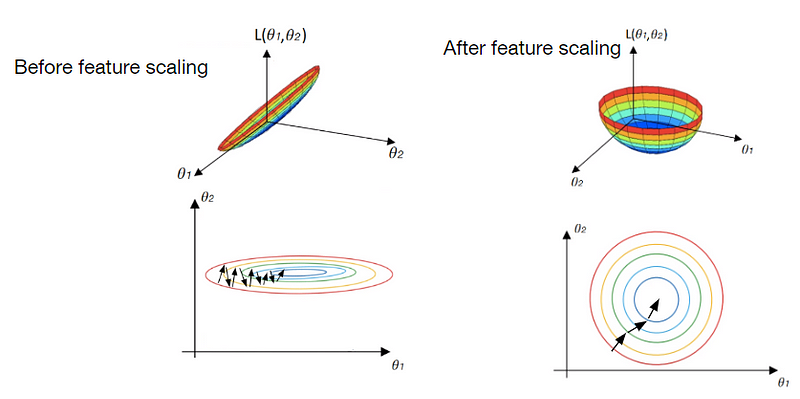
Auf der linken Seite sehen Sie unsere Verlustfunktion mit ihren Zählern ohne Merkmalsskalierung, wie sie zuvor gesehen wurde. Auf der rechten Seite sehen Sie die gleiche Verlustfunktion nach der Merkmalsskalierung von und . Es ist deutlich zu erkennen, dass die Vereinheitlichung der Features und dazu geführt hat, dass die Verlustfunktion symmetrischer geworden ist.
In diesem Fall kann der Gradientenabstieg geradewegs auf das Minimum der Verlustfunktion zusteuern, ohne zu schwanken. Außerdem können wir so eine viel höhere Lernrate verwenden, was die gesamte Trainingszeit des Modells verkürzt.
Nachdem wir nun die Vorteile der Merkmalsskalierung gesehen haben, wollen wir uns mit der Frage befassen, wie die Merkmalsskalierung in der Praxis durchgeführt werden kann. Es hat sich herausgestellt, dass es mehrere Möglichkeiten gibt, dies zu tun.
3.2 Min-Max-Skalierung
Der einfachste Weg, die Features zu standardisieren, ist die Skalierung dieser Features auf einen neuen Bereich zwischen 0 und 1. Dies kann durch die folgende Gleichung erreicht werden:
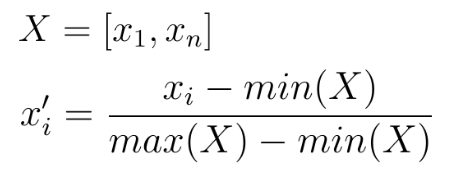
Für ein gegebenes Merkmal  , das Werte zwischen
, das Werte zwischen  und
und  enthält, subtrahiert man von jedem Wert in diesem Bereich den niedrigsten Wert in und teilt die Lösung durch die Differenz zwischen dem höchsten und dem niedrigsten Wert in . Dieses Verfahren bewirkt, dass alle Werte eines Merkmals neue Werte im Bereich 0 -1 annehmen.
enthält, subtrahiert man von jedem Wert in diesem Bereich den niedrigsten Wert in und teilt die Lösung durch die Differenz zwischen dem höchsten und dem niedrigsten Wert in . Dieses Verfahren bewirkt, dass alle Werte eines Merkmals neue Werte im Bereich 0 -1 annehmen.
Diese Skalierungsmethode hängt nicht von einer zugrunde liegenden Verteilung von ab. Schauen wir uns an, wie diese Skalierung bestimmte Merkmalswerte verändert.
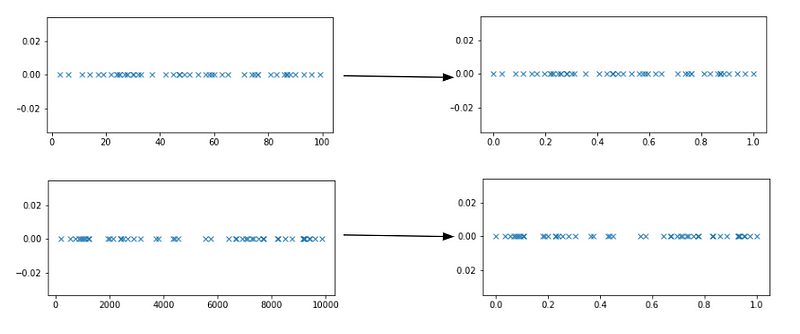
Oben links sehen Sie das Diagramm der zufällig erzeugten Zahlen in einem Bereich zwischen 0 und 100. Das folgende Diagramm zeigt dieselbe Verteilung, allerdings für einen viel größeren Bereich. Betrachten Sie diese beiden Diagramme als Beispiel für zwei Features in einem Datensatz, die sehr unterschiedliche Bereiche haben.
Wenn Sie die auf der vorherigen Folie vorgestellte Skalierungsmethode anwenden, können Sie sehen, dass alle diese Werte in einen viel dünneren Bereich projiziert werden. Unabhängig von den vorherigen Bereichen liegen nun alle Werte in einem Bereich zwischen 0 und 1, nur die relativen Proportionen sind gleich geblieben.
In Python können Sie diese Technik zur Skalierung von Features mit Hilfe der sklearn-Bibliothek implementieren. Der folgende Code zeigt, wie diese Technik in der Praxis umgesetzt werden kann.
3.2 Normalisierung
Eine weitere Technik für den Umgang mit sehr unterschiedlichen Merkmalsbereichen ist die Anwendung der Normalisierung. Bei der Normalisierung müssen Sie Ihr Merkmal als einen einfachen mathematischen Vektor behandeln. Dies ist überhaupt kein Problem, da alle Werte von numerisch sind und jeder Wert in einen Eintrag in einem Vektor darstellen würde.
Im nächsten Schritt dividieren Sie jedes Element in Ihrem Merkmalsvektor durch die Norm des Vektors :
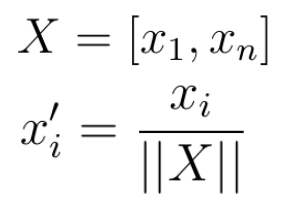
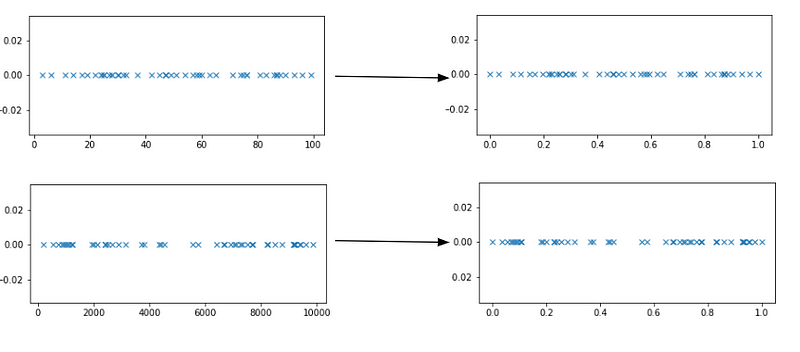
Als Norm können Sie die Manhattan-Norm oder die einfache euklidische Norm verwenden. Durch die Anwendung der Normierung wird die Größe jedes Wertes in aufgehoben und sie werden gezwungen, Werte zwischen 0 und 1 anzunehmen.
Schauen wir uns an, wie das in der Praxis aussieht. Wie zuvor sehen Sie auf der linken Seite die Diagramme von Zufallswerten aus zwei sehr unterschiedlichen Bereichen. Die entsprechenden Werte nach der Normalisierung sind auf der rechten Seite zu sehen:
Der folgende Python-Code zeigt, wie die Normalisierung in der Praxis angewendet werden kann:
3.3 Standardisierung
Die dritte Methode, die verwendet werden kann, um den Bereich von Features neu zu skalieren, heißt Standardisierung. Die Standardisierung von Features bewirkt, dass die Werte eines Merkmals einen Mittelwert von Null (bei Subtraktion des Mittelwerts im Zähler) und eine Varianz von Eins haben.
Um eine Standardisierung durchzuführen, müssen Sie zunächst den Mittelwert und die Standardabweichung der Werte in Ihrem zu standardisierenden Merkmal berechnen. Im nächsten Schritt subtrahieren wir den Mittelwert  von jedem Merkmalswert und teilen die resultierende Differenz durch die Standardabweichung:
von jedem Merkmalswert und teilen die resultierende Differenz durch die Standardabweichung:
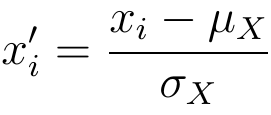
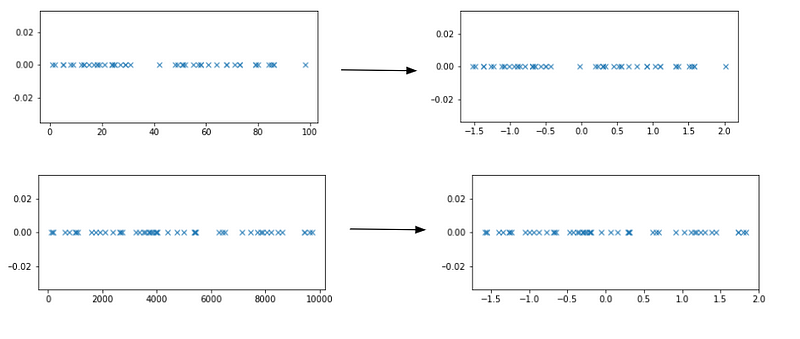
Wie zuvor sehen wir uns an, wie diese Technik auf zwei sehr unterschiedliche Wertebereiche angewendet wird. Es ist zu erkennen, dass in diesem Fall nach der Standardisierung alle Werte um den Mittelwert Null herum verteilt sind und die meisten Werte innerhalb der Einheitsvarianz liegen:
Der folgende Codeschnipsel zeigt, wie die Standardisierung in Python angewendet werden kann, wobei wiederum die Sklearn-Bibliothek verwendet wird:
5. Umgang mit fehlenden Werten
Leider gibt es in der Praxis oft Datensätze, die fehlende Werte enthalten. Fehlende Werte in einem Datensatz werden oft als ‚NaN‘, ‚NA‘, ‚Keine‘, “, ‚?‘ dargestellt.
So enthält beispielsweise der berühmte Datensatz „Weinqualität“ eine ganze Reihe fehlender Werte:
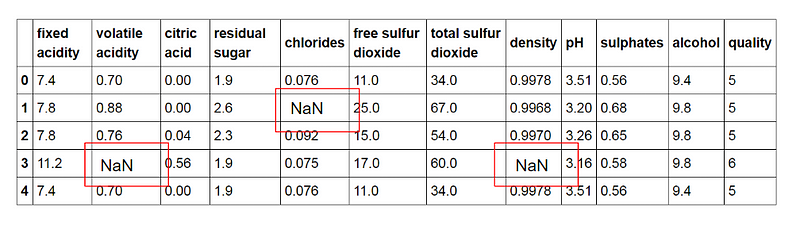
Dies ist natürlich ein Problem, das angemessen behandelt werden muss, da neuronale Netze und maschinelle Lernmodelle mit dieser Art von Daten nicht arbeiten können.
Zunächst einmal sollte ich erwähnen, dass es keinen perfekten Weg gibt, um mit fehlenden Daten in Ihrem Datensatz umzugehen. In den meisten Fällen sollten Sie einfach verschiedene Methoden ausprobieren und sehen, was Ihnen die besten Ergebnisse liefert.
Im Folgenden möchte ich Ihnen zwei Techniken zum Umgang mit fehlenden Daten vorstellen, mit denen ich in der Vergangenheit zufriedenstellende Ergebnisse erzielt habe. Die erste Technik ist sehr einfach: Sie löschen einfach die gesamte Datenstichprobe, in der der fehlende Wert auftritt:
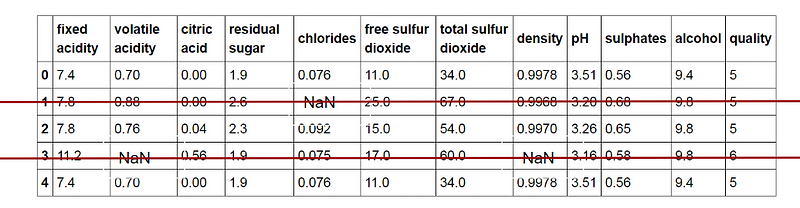
Mit dieser Technik wird das Problem der fehlenden Werte vollständig beseitigt. Ein großer Nachteil ist jedoch die Tatsache, dass sich durch das Löschen der Datenproben der Umfang Ihres Datensatzes verringert.
Das mag kein Problem sein, wenn Sie einen riesigen Datensatz mit Millionen von Stichproben und nur ein paar hundert fehlenden Werten haben. Da die Leistung eines neuronalen Netzes und eines Modells für maschinelles Lernen ungefähr mit der Größe des Datensatzes skaliert, kann das Löschen von Stichproben in einem sehr kleinen Datensatz die Leistung Ihres Modells drastisch verringern.
An dieser Stelle kommt die Technik der Datenimputation zum Tragen. Bei der Datenimputation wird ein fehlender Wert durch einen bestimmten, von Ihnen berechneten Wert ersetzt. Dieser berechnete Wert ist sehr oft entweder der Mittelwert, der Median oder der Modus der Werte innerhalb des Merkmals, in dem der fehlende Wert auftritt. Schauen wir uns ein Beispiel an. Hier sehen Sie noch einmal die ersten paar Stichproben des Weinqualitätsdatensatzes, bei denen drei verschiedene Features einen fehlenden Wert enthalten:
Im Imputationsschritt berechnen wir in diesem Fall den Mittelwert aller Werte eines Merkmals, in dem die fehlenden Werte beobachtet werden.

Danach ersetzen wir die fehlenden Werte durch die berechneten Mittelwerte:

Bitte beachten Sie, dass die Imputation nicht unbedingt zu besseren Ergebnissen führt. Meiner Meinung nach ist es jedoch immer besser, Daten zu behalten, als sie zu verwerfen. Dennoch würde ich persönlich die Imputation in jedem Fall der Löschung vorziehen.
6. Umgang mit Ausreißern
Lassen Sie uns nun darüber sprechen, wie wir mit Ausreißern in unserem Datensatz umgehen können. Ausreißer sind Dateninstanzen, die sich in ihren Werten deutlich von anderen Instanzen im Datensatz unterscheiden.
Zum Beispiel: [0.5, 0.41, 0.75, 27.4, 0.1, 2.78]
Oftmals sind Ausreißer harmlos. Dabei kann es sich nur um statistische Ausreißer oder Fehler in den Daten handeln. Allerdings können Ausreißer manchmal den Trainingsprozess eines neuronalen Netzes oder eines Modells für maschinelles Lernen für uns problematisch machen.
Wie im Falle fehlender Werte gibt es auch hier keine perfekte Lösung für den Umgang mit diesen besonderen Vorkommnissen. Die meisten Methoden für den Umgang mit Ausreißern ähneln den Methoden für fehlende Werte. Der einfachste Weg, Ausreißer loszuwerden, ist, sie zu löschen.
Die meisten Methoden zum Umgang mit Ausreißern ähneln den Methoden für fehlende Werte, wie z. B. das Löschen von Beobachtungen, das Transformieren, das Binning, die Behandlung als separate Gruppe, die Imputation von Werten und andere statistische Methoden. Im Folgenden werden die gängigen Techniken zur Behandlung von Ausreißern erörtert. Wie bei der Imputation fehlender Werte können wir auch Ausreißer imputieren.
Wir können Methoden zur Imputation von Mittelwert, Median und Modus verwenden. Eine weitere mögliche Methode ist die Anwendung bestimmter Transformationen. Die Logarithmierung aller Werte innerhalb des Merkmals, in dem der Ausreißer auftritt, würde die durch Extremwerte verursachte Variation verringern.
Eine weitere mögliche Transformation wäre die Binarisierung, bei der alle Werte eines Merkmals anhand eines binären Schwellenwerts transformiert werden. Alle Werte, die über dem Schwellenwert liegen, werden mit 1 und alle Werte, die gleich oder niedriger sind, mit 0 gekennzeichnet. Wenn es eine signifikante Anzahl von Ausreißern gibt, sollten wir sie im statistischen Modell getrennt behandeln. Einer der Ansätze besteht darin, beide Gruppen als zwei verschiedene Gruppen zu behandeln und für beide Gruppen ein eigenes Modell zu erstellen und dann die Ergebnisse zu kombinieren.
6. Kategoriale Daten und String-Datentypen
In den vorangegangenen Abschnitten wurden verschiedene Vorverarbeitungstechniken für kontinuierliche numerische Daten erörtert. In dieser Vorlesung befassen wir uns mit einer anderen Art von Daten, die diskret sind und gemeinhin als kategorische Daten bezeichnet werden.
Kategoriale Daten sind Daten, die diskret sind und im Allgemeinen eine begrenzte Anzahl möglicher Werte annehmen, wie z. B. „Alter“, „Geschlecht“, „Land“ usw.
Normalerweise finden Sie kategorische Daten als String-Datentyp in Ihrem Dataset. Das muss aber nicht immer der Fall sein. Zum Beispiel ist „Alter“, eine diskrete, kategoriale Variable, ein Integer-Datentyp.
Im Falle von kategorischen String-Daten können neuronale Netze und andere Modelle für maschinelles Lernen nicht mit dieser Art von Daten arbeiten. Wir müssen einige Änderungen und Transformationen an diesen Daten vornehmen, bevor wir ein Modell darauf trainieren können.
Der gesamte Prozess der Konvertierung kategorischer String-Daten in ein Format, das von Deep-Learning- oder Machine-Learning-Modellen verwendet werden kann, wird im Folgenden behandelt.
6.1 Kodierung
Schauen wir uns ein kategorisches Merkmal eines Datensatzes mit der Bezeichnung „Job“ an. Dieses Merkmal enthält String-Werte, die für verschiedene Berufsbezeichnungen stehen:

Natürlich können wir diese Werte nicht verwenden und sie in ein neuronales Netz oder ein anderes maschinelles Lernmodell einspeisen. Zunächst müssen wir die kategorischen String-Daten in ein numerisches Datenformat umwandeln. Dieser Vorgang wird als Kodierung bezeichnet.
Bei der Kodierung wird jedem Zeichenfolgenwert ein numerischer Wert zugewiesen, wobei identische kategorische Werte die gleichen numerischen Werte haben:
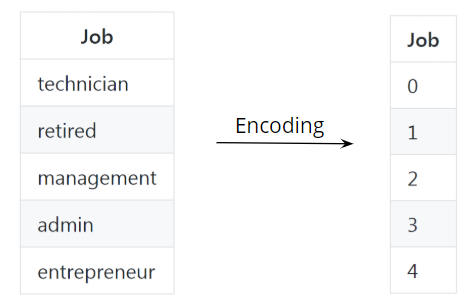
Sie können diesen Schritt von Hand durchführen oder einfach die eingebaute Sklearn-Funktion namens LabelEncoder verwenden:
An diesem Punkt denken Sie vielleicht: Okay, wir haben, was wir wollten. Wir haben alle Strings durch numerische Werte ersetzt, wir sind fertig. Aber leider ist es nicht so einfach, wie es auf den ersten Blick scheint.
Obwohl wir diese Werte in ein neuronales Netz einspeisen könnten, würden wir beim Training ein Problem verursachen, weil die Features immer noch kategorisch sind.
Das Problem besteht darin, dass wir den Zeichenkettenwerten recht willkürlich numerische Werte zugewiesen haben. Tatsächlich wurden die Werte in aufsteigender Reihenfolge vergeben, abhängig von der Position der kategorischen String-Dateninstanz im Datensatz. Infolgedessen konnte unser Modell während des Trainings höheren Zahlenwerten eine höhere Bedeutung zuweisen.
In diesem speziellen Beispiel hat die Berufsbezeichnung „Unternehmer“ einen höheren numerischen Wert als die Berufsbezeichnung „Admin“. Im wirklichen Leben würden einige argumentieren, dass der Beruf des Unternehmers in der Tat einen höheren Stellenwert hat. Bei der Ausbildung eines algorithmischen Modells ist dies jedoch nicht notwendig.
Vielmehr hängt es von dem gegebenen Problem ab, das wir zu lösen versuchen, ob die gegebene Berufsbezeichnung für dieses spezielle Problem wichtiger ist oder nicht.
Durch die Verwendung kategorischer Daten würden wir eine Voreingenommenheit gegenüber einem bestimmten Berufsmerkmal einführen.
Denken Sie daran, dass der Zweck eines Deep-Learning-Modells darin besteht, wichtige Muster und Beziehungen in den Daten zu erkennen und daraus zu lernen.
Das bedeutet, dass ein bestimmter Satz von Gewichten gefunden werden soll, der es dem Netzwerk ermöglicht, eine korrekte Vorhersage für die eingegebenen Features zu treffen. Während des Trainings müssen wir das neuronale Netz selbst entscheiden lassen, wie und in welchem Ausmaß eine bestimmte Berufsbezeichnung und der dazugehörige numerische Wert zur Lösung des gegebenen Problems beitragen.
Wenn wir diese Voreingenommenheit einführen, wird das Netz möglicherweise nicht oder zumindest nicht so leicht die erforderlichen Gewichte finden. Denn:
- Erstens müsste das Netz diese Verzerrung erkennen
- Zweitens muss es geeignete Korrekturen an den Gewichten vornehmen, um diese Verzerrung zu neutralisieren.
Das Problem der Einführung einer Verzerrung durch die Verwendung kategorialer Daten kann durch eine Technik gelöst werden, die als One-Hot-Encoding bezeichnet wird.
6.2 Ein-Hot-Codierung
Bei der One-Hot-Codierung wird eine Binarisierung der kategorialen Werte durchgeführt. In unserem Fall haben wir während der Kodierung den kategorialen String- Features numerische Werte zugewiesen. Dann haben wir einen Vektor erhalten, in dem die String-Werte durch numerische Werte ersetzt wurden.
Während der One-Hot-Codierung erstellen wir für jeden kategorialen Merkmalswert einen spärlichen Zeilenvektor. Dieser Vektor enthält nur Nullen mit Ausnahme eines einzigen Eintrags, der den Wert Eins hat. Der Index dieses Eintrags entspricht dem numerischen Wert, auf den die One-Hot-Codierung angewendet wird:
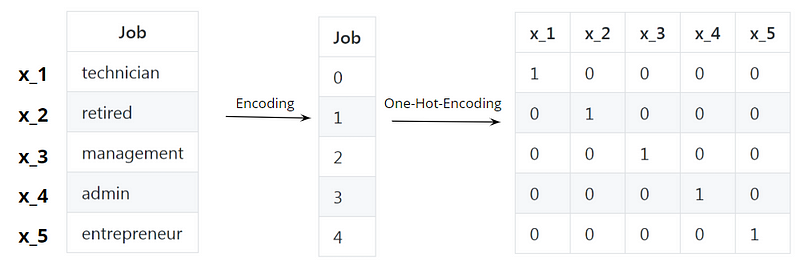
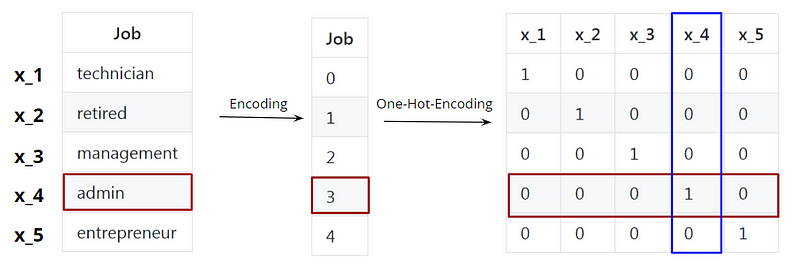
In unserem Beispiel hat die Berufsbezeichnung „admin“ den kodierten Wert 3. Der one-hot-kodierte Vektor dieser Berufsbezeichnung hat in der vierten Spalte, die dem Index Nr. 3 entspricht, den Wert 1. Zur Erinnerung: In einem Vektor beginnen die Indizes bei Null.
Die Spalten stellen die Berufsbezeichnungen dar. Ich habe die Titel mit den Namen bis  abgekürzt. Die Spalte
abgekürzt. Die Spalte  steht also für den Titel admin.
steht also für den Titel admin.
Eine Person in einem Datensatz mit dieser Berufsbezeichnung admin hätte einfach den Wert 1 in der Spalte, die diese Berufsbezeichnung darstellt, und ansonsten Nullen, genau wie hier:
Mit der One-Hot-Codierung werden wir kategorische Daten los und stellen sicher, dass alle Merkmalseinträge zu Beginn des Trainings gleich behandelt werden. Die Bedeutung eines Merkmals für die Vorhersage des Netzes wird erst während des Trainings des neuronalen Netzes bestimmt.
Eine einfache und schnelle Implementierung von One-Hot-Encoding, angewandt auf das vorherige Beispiel, kann mit der sklearn OneHotEncoder Funktion durchgeführt werden:
7. Aufteilung des Datensatzes in Training-, Test- und Validierungsdaten
Bevor wir unser neuronales Netz trainieren können, müssen wir noch einen letzten Schritt tun. Wir müssen unseren Datensatz in so genannte Trainings-, Validierungs- und Testsätze unterteilen.
Der Trainingssatz ist, wie der Name schon sagt, der Datensatz, mit dem wir das Netz trainieren. Das Modell sieht diese Daten und lernt daraus.
Im Gegensatz dazu dient der Validierungssatz dazu, ein Modell unvoreingenommen zu bewerten, während wir das Netz trainieren, die Hyperparameter anpassen und verschiedene Modellarchitekturen ausprobieren. Die Bewertung ist unvoreingenommen, da das Modell diese Daten während des Trainings nur gelegentlich sieht, um einige Bewertungsmetriken zu berechnen, aber das Netz lernt nie aus diesen Daten.
Sobald ein Modell vollständig trainiert ist, wird seine endgültige Leistung mit dem Testdatensatz getestet. Der Testdatensatz stellt den Goldstandard dar, um die endgültige Leistung eines trainierten Modells wirklich zu bewerten. Sehr oft wird der Validierungsdatensatz als Testdatensatz verwendet, aber das ist keine gute Praxis.
Eine knifflige Frage könnte sein, welches Verhältnis für diese drei separaten Datensätze verwendet werden sollte.
Im Allgemeinen sollte die Trainingsmenge so groß wie möglich sein. Andererseits müssen Sie für die Validierung und vor allem für die Testphase genügend Daten zur Verfügung stellen, um ein aussagekräftiges Leistungsergebnis zu erhalten.
In den meisten Fällen müssen Sie das Verhältnis an die Größe Ihres gesamten Datensatzes anpassen. Bei mittelgroßen Datensätzen mit einigen Tausend bis Zehntausend Datenproben werden in der Regel 70 % der Datenproben in den Trainingssatz, 10 % in den Validierungssatz und der Rest in den Testsatz aufgenommen.

In diesem Fall sind Sie in der Lage, genügend Beispiele für Ihr neuronales Netz bereitzustellen und gleichzeitig Ihr Modell genau zu bewerten und zu testen.
Wenn Sie auf sehr große Datensätze mit Millionen von Datenbeispielen stoßen, können Sie die Größe der Validierungs- und Testsätze erheblich reduzieren. Nur ein paar Prozent dieser Millionen von Dateninstanzen sind mehr als genug, um die Leistung Ihres Modells zu testen.

Mit der Klasse sklearn.model_selection können Sie einen beliebigen Datensatz in zwei getrennte Datensätze aufteilen, die z. B. für Trainings- und Testzwecke verwendet werden können:
Willst Du einen Job in Data Science und AI?
Gerade als Quereinsteiger oder kompletter Berufseinsteiger ist es mittlerweile nahezu unmöglich, einen Job im Bereich AI/Data Science zu ergattern.
Mittlerweile gibt es durchschnittlich einhundert Bewerber auf jede Stelle und es kommt mir so vor, als hätte jeder, der sich bewirbt, bereits mehrere Online-Kurse zum Thema Data Science absolviert und ein halbes Dutzend Zertifikate vorzuweisen.
Ohne aus dieser großen Masse an Kandidaten herauszustechen, landet die Bewerbung schnell im virtuellen Mülleimer.
Als Teamleiter im Bereich KI/Data Science habe ich im Laufe der Jahre Bewerbungen von Hunderten von Kandidaten gesehen. Ich weiß, worauf es ankommt.
Ein Quereinsteiger oder Berufseinsteiger ohne nennenswerte Erfahrung hat nur eine Chance, den Job zu bekommen: mit einem umfangreichen Data-Science-Portfolio, das perfekt auf die ausgeschriebene Stelle zugeschnitten ist. Damit überzeugst du die HR und die Entscheidungsträger warum gerade Du der richte Kandidat für die Stelle bist.
Ich unterstütze dich persönlich dabei, ein maßgeschneidertes Data-Science-Projektportfolio zu entwickeln und umzusetzen, das genau auf deine Wunschstelle zugeschnitten ist.
Interesse? Dann, trage unten deinen Namen und Email ein und ich melde mich bei dir mit weiteren Informationen.




Super Artikel, sehr klar und nachvollziehbar und gut erklärt warum die Transformation gemacht werden muss. Vielen Dank